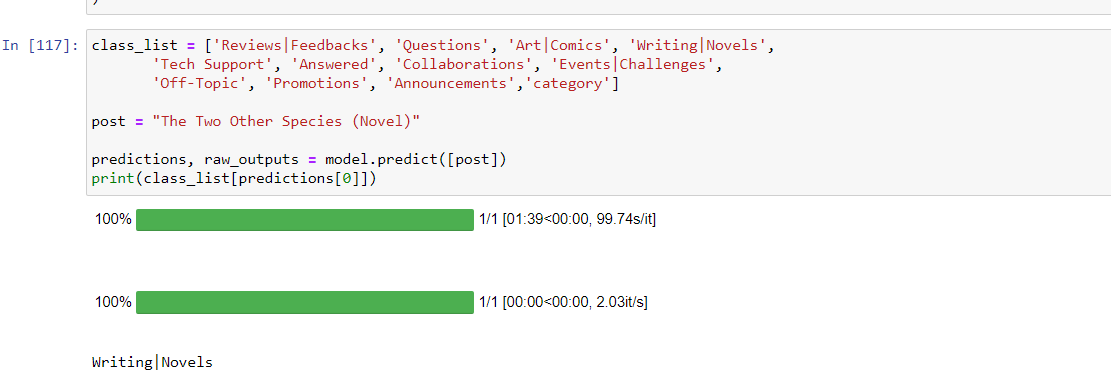
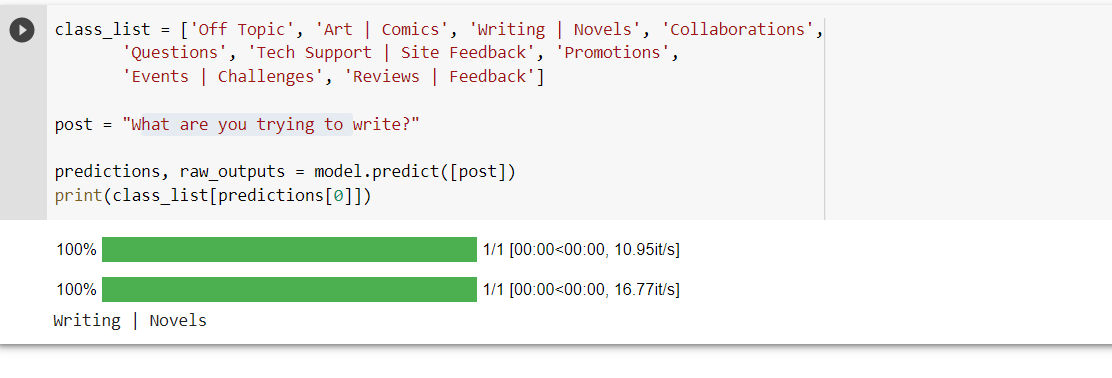
Technical Areas worked on :
- Started scraping Tapas forum using Beautiful Soup. Installed Selenium and the webdriver for further scraping.
- Refreshed workflow knowledge of Git & Github environments.
- Worked with Trello to streamline project flow for the team.
- Set up the discord server for team communication.
Tools
- Jupyter Notebook
- Trello
- Discord
- Git & Github
Soft Skills
- Working alongside other leads to develop a streamlined project workflow for the team (Team management & leadership)
- Time management skills (Making sure the time set for meetings is convenient for people from all time-zones)
- Collaboration and Team-work (Having ice-breakers each session to ensure a comfortable, collaborative environment and scrum meetings every day to clarify doubts)
Three achievement highlights:
- Managing to work with a team majorly from a different time zone.
- Ran into an issue with Selenium that took almost half a day to troubleshoot but eventually got it resolved.
- Forming a rapport with the team and co-leads to ensure smooth progress of the project.
1 Like
Machine Learning - Level 1 Week 2 Self Assessment
Technical Areas worked on :
- Scraped the Tapas Forum using Selenium. Scraped up all the titles, comments, categories and dates of all the titles containing the word ‘meme’.
- Converted the data into csv format and a dataframe using pandas.
- Used a third party software (Nvivo) to generate a word cloud.
- Performed elementary EDA on the data. Referred to the EDA tutorial on the STEM-Away forum and calculated no of words, no of characters, average word length, no. of stopwords and performed basic pre-processing such as removing punctuation & stopwords, stemming and tokenization.
- Additionally, pushed testcode to github repo.
Tools/Libraries
- Jupyter Notebook
- Python
- Git/Github
- nltk and sklearn libraries
- Selenium and Beautiful Soup
- Trello
- Nvivo (third party qualitative research software)
- Pandas
Soft Skills
- Team Management : Set up the agenda for the week, arranged meetings with fellow leads and team-mates and made sure that everyone is on the same page with respect to deliverables.
- Collaboration and Communication : Fostered a healthy rapport with fellow leads and worked alongside them to determine best practices for better team output. We are in constant communication via leads discord channel to address immediate doubts/clarifications.
- Task Management : Divided the team into two sub-groups on the basis of time-zones to ensure more efficiency and teamwork.
- Tech help : Organizing scrum meetings everyday for 10 minutes in case of any tech assistance required by any team member. Demonstrated a quick 10 minute overview of libraries installation in one of the scrums.
- Time Management skills : Made sure that the time of meetings is convenient for everyone.
Three achievement highlights
- Debugging : Working with Selenium proved to be a little tough but eventually worked around the issues. The Xpaths kept changing everytime I loaded a fresh application of the forum and I had to find more robust methods to improve the code.
- Steep learning curve : The week was filled with fast paced learnings from working with selenium to figuring EDA out.
- Co-moderating the team sessions : Leading certain sections of team meetings by explaining the week deliverables and clarifying doubts have been wonderful in terms of exploring my personal leadership style.
Goals for the week
- Completing advanced text processing and visualisations. (N-grams, TF-IDF, Word Embeddings and word clouds using python)
- Dwelling more into NLP resources
- Making sure that the team has completed module 2 deliverables by the end of the week and has module 3 requisites prepared.
(A word cloud of my scraped data generated via Nvivo before pre-processing and cleaning the data)
Machine Learning - Level 1 Week 3 Self Assessment
Technical Areas worked on :
- Re-worked my scraper to scrape ~13,000 titles, replies and views, category-wise from the Tapas forum.
- Stored the data in 11 separate csv files and eventually combined them into one csv file.
- Performed EDA tasks on my data as follows -
a. Calculated frequency of rare and most common words in the data and plotted them.
b. Calculated the word length and the average word length of each title
c. Removed stop-words and converted the data into lowercase.
d. Plotted unigram, bigram and trigrams of all the titles with views greater than 100.
e. Performed sentiment analysis of the data.
f. Obtained a sparse matrix using TF-IDF method
g. Ran the code for bag-of-words method on the data.
Tools/Libraries :
- Jupyter Notebook
- Python
- Git/Github
- nltk and sklearn libraries
- Selenium
- Pandas/Numpy
- Trello
Soft Skills :
- Team Management : Set the agenda for the week, met co-leads, held team-meetings and prepared a deliverables document for Module 3 Week 1 for the team to follow.
- Help and collaboration : Helped resolve errors/divided up the work/provided resources for team-mates to follow via scrum-meetings and discord channels.
Three achievement highlights :
- Figured out an efficient way to scrape the forum just by using Selenium and re-tweaked the code to yield 10k+ data samples.
- Figured out what EDA methods worked and what methods didn’t work in the process. For eg : Spelling correction and stemming distorted my data quite a bit, so I decided to not employ those functions in my EDA.
- Helped streamline team progress by preparing a clear deliverables document for every team-member to follow. The document lays out all the tasks to be finished and all the module 3 requisites to be prepared by the end of this week.
Goals for the week
- Delve more into the intuition of advanced EDA concepts such as word embeddings and bag of words.
- Read up on cosine similarities.
- Watch STEM-Away tutorials on recommendation systems.
- Prepare a progress deck till Module 2 with the team to exhibit to the mentors and start discussing the ML pipeline for our recommendation system.
(A snapshot of the n-grams plotted for the scraped data)
Machine Learning - Level 1 Week 4 Self Assessment
Technical Areas worked on :
- Understood the intuition behind word embeddings and different distance metrics and ran TF-IDF and cosine similarity on my pre-processed data.
- Ran a BERT-based classifier on my data and managed to classify a title to its appropriate category.
- Read several articles on recommender systems (content-based and collaborative-filtering).
- Installed and explored PyTorch and TensorFlow libraries.
- Pushed my module 2 code, csv files and visualisations to the team repo.
Tools/Libraries
- Jupyter Notebook
- Python
- Scikit-Learn
- PyTorch & TensorFlow
- Pandas/Numpy
- Trello
- Git/Github
Soft Skills :
- Set up the agenda for the team meeting and brainstormed the deliverables and roadmap with co-leads.
- Attended scrum meetings to resolve and troubleshoot queries; explained a general overview of Module 3 expectations to the team and prepared a document for the same, complete with resources.
Three achievement highlights :
- Got around to the concepts of word embeddings and cosine similarity, which seemed a bit complex at first.
- Figured out a general roadmap of an ML pipeline for a recommender system and the concepts/libraries that need to be understood and deployed.
- Attended office hours with Sara to figure out team logistics.
- Attended an ML session 1 presentation to get insights into how the final product is to be delivered.
Goals for the week :
- Play around with some additional visualizations (Word embeddings using TSNE)
- Charter a problem statement with co-leads to work towards.
- Charter a clear road-map with co-leads on how the work is to be divided moving forward.
- Explore more python libraries and associated concepts and start working on the recommender system in accordance with the problem statement alongside the team.
(Snapshot of the BERT based classifier)
Machine Learning - Level 1 Week 5 Self Assessment
Technical Areas worked on :
1, Trained different combinations of word embeddings and classifiers on the data to figure out the best performing one :
(As perfomed on the csv file selected as the team csv) :
a. TF-IDF + Naive Bayes
b. TF-IDF + SVM
c. Word2Vec + Naive Bayes
d. Word2Vec + SVM
e. TF-IDF + Logistic Regression
f. TF-IDF + SVM (along with hyperparameter tuning)
g. TF-IDF + Random Forest (along with hyperparameter tuning)
h. TF-IDF + Bagging Trees (along with hyperparameter tuning)
g. TF-IDF + XGBoost (along with hyperparameter tuning)
h. Additionally, ran Roberta on the data personally scraped.
The combination of TF-IDF and SVM along with hyperparameter tuning yielded the best results
- Gleaned a better insight on BERT and BERT family of classifiers (RoBERTa, XLNet, DistilBERT) and and its architecture via several articles.
Tools/Libraries
- Jupyter Notebook
- nltk
- Scikit-Learn
- Pandas/Numpy
- Trello
- Git/Github
- Gensim
- Gridsearch CV
Soft Skills :
- Met the co-leads multiple times over the week and finalized on the : a. Problem Statement for the Recommender System b. Sub-teams for classifiers and recommendation system to improve team efficiency. c. One common, most comprehensive csv file for the whole team to work on.
- Explained week deliverables during the team meeting, stressed on the importance of amping up inter-team communication and made a comprehensive document of deliverables to be completed for the week (along with resources)
- Attended office hours with Anubhav to clarify doubts with respect to the ML pipeline and the problem statement.
Three achievement highlights
- Read about and understood the non-directional nature of BERT classifier and deeper insights into its architecture.
- Ran a bevy of classification models and learnt how to implement GridSearch CV for hyperparameter tuning.
- Clarified team members’ questions / doubts via Discord and Scrum.
Goals for the week :
- Explore more classification models/ensemble models and pipelines for the data. Also focus on making the accuracy better.
- Explore deep learning frameworks/neural networks for classification of the data
- Run more sophisticated word embeddings (such as TF-IDF + BERT)
- In tandem, start working on building the recommender system.
- Run confusion matrices after having trained the data to gain an overall picture of model performance (and not just accuracy in silos)
- Trace team progress and work towards integrating everyone’s contributions into one complete team deliverable.
- Some models proved to be very computationally expensive (BERT, XGBoost). Figure out some work-arounds for that.
- Towards the end of the week, focus on how to deploy the web app for our deliverable.
(Snapshot of TF-IDF + SVM hyperparameter tuning ~ yielded an accuracy of 96%)
Machine Learning - Level 1 Week 6 Self Assessment
Technical Areas worked on :
- Trained advanced classification models on data ;
a. BERT b. XLNet c. DistilBERT d. Electra
- Ran confusion matrix for each of the previously trained classification models.
- Attempted to bump the accuracy metrics via hyperparameter tuning.
- Made a basic recommender system
Tools/Libraries
- Google Colab/Jupyter Notebook
- SimpleTransformers
- Pandas/Numpy
- Tokenizers (HuggingFace)
- GridSearch CV
- Trello
- Gensim
Soft skills :
- Finalized the deliverable to be deployed on the app alongside the leads and the team. (Best performing classifier).
- Helped divide work among the leads and team to catalyze team progress.
- Set an internal deadline for the team to finish their deliverables so that we can progress to the final stage of app development.
Three achievement highlights :
- Achieved ~95% accuracy (and equivalent Precision, Recall, F1 metrics) for my TF-IDF + SVM model using hyperparameter tuning. Although, my highest simple transformers’ accuracy is 67% (that of Electra).
- Figured a work-around for a faster deployment of BERT models. (Using the GPU option on Google Colab)
- Helped streamline team progress.
Goals for the week
- Try and push my accuracy past 70% for my BERT models.
- Start working and collaborating with my team members on the app and app deployment.
- Start working on the team progress deck.

(Confusion matrix for my highest accuracy classifier)
(Metrics for my highest accuracy classifier)
(Classification example using Electra)
Machine Learning - Level 1 Week 7 Self Assessment
Technical Areas Worked on :
- Iterated over different hyperparameter tuning techniques to bump up accuracy for all the simple transformer models : a. GridSearchCV b. Bayesian Optimization c. Population Based Training
- Provided the code file of my highest performing model (XLnet) to the co-lead overseeing the deployment of the web-app to run a demo version of the web app based classifier.
- Understood the web deployment pipeline and ran the flask code for my model to create a locally deployed web-app. (But ran into a few errors with my tar-files)
Tools/Libraries
- Google Colab/Kaggle Notebooks
- Flask
- Pandas/Numpy
- Tokenizers
- ray[tune]
- Simple Transformers
Soft skills :
- Worked on the final deck alongside the team
- Met with the team in consecutive 4-day meetings to fine tune the process and wrap the deliverables up
Three achievement highlights :
- Exhausted my GPU resources on Google Colab but pivoted to Kaggle notebooks as a work-around.
- Kept at hyperparameter tuning till I got a satisfactory bump in the accuracy. (Though I faced a couple of errors with the PBT tuning)
- Finished portions of the deck and successfully wrapped up the deliverables alongside the team
Goals for the week
- Present our final deck to mentors and seek constructive feedback to improve for future.
- Exchange Linkedin handles/social media handles with the team to stay in touch.
(XLnet metrics - My highest performing simple transformer model)