Module1
Concise overview of things learned:
Technical area:
-
Understood how to extract raw Medline sentences through PubMed parser
-
Learned about Drug-Target relationships, working of Drugs, Vector Space models, Literature mining by reading prerequisite & supplementary materials given.
-
Read the exact research paper to deep dive into what is to be done
Tools:
Request Library, Pubmed_Parser, nltk , gzip module , Trello
Softskills:
-
Learned to work in teams, divided the whole task into subtasks & then compiled them to complete the task in time.
-
Learned how to use Trello for structuring & managing the project in a easy way.
-
Improved communication skills while interacting with other team members during team meetings & for the very first time worked on Presentation slides for Team wide & Pathway wide Journal Clubs.
Achievement highlights:
-
Presented the research paper called “Literature Mining for Biologists” & some parts of the exact research paper in the team wide journal clubs
-
Presented the result part of the exact research paper to the pathway wide journal club
-
Extracted the raw Medline sentences using pubmed_parser
Detailed Statement of Tasks Completed:
- For extracting raw Medline text task main motive was to collect all the drug-gene pairs & extract only those sentences which contain atleast a drug-gene pair. I downloaded the drug-gene pairs from Pharmgkb & drug list from Drug-Bank (it took a lot of time to get approval from DrugBank). One of our team members John explained us how to extract .xml files. With that help I used requests module & pubmed_parser for extracting raw data & gzip library for .xml files. Then I created a list of drugs & genes with the data from PharmGKB & Drugbank. It has 17K unique drugs & 20K unique genes. After extracting the raw sentences I used nltk library for tokenization. Then I checked whether the token is present in the drug or gene list ,if present added to the usable_sentences list & stored the data in .tsv format. I was able to extract more than 2000 raw Medline sentences.
Goals for the upcoming week:
- Dependency parsing of raw data & creating the dependency matrix for EBC algorithm.
1 Like
Module2
Concise overview of things learned:
Technical area:
-
Learned about dependency parsing, TRANSITION based dependency parser, 3 TRANSITION ACTIONS(Shift, Left - Arc, Right - Arc) & why Stanford parser stands out from other parsers, mathematics behind Stanford parser from the training material given.
-
Learned how to use dependency parsing of raw Medline data with Java & store the output in .txt file
-
Learned spacy for dependency parsing , sparse matrix & read all the prerequisite & supplementary research paper given.
Tools:
spacy, Stanford parser 3.5.0 version, Java VM, jython 2.7.2
Soft-skills:
- Improved communication skills while interacting with other team members during team meetings & Team wide Journal Clubs.
Achievement highlights:
-
Successfully completed the dependency parsing task of raw Medline sentences with Java
-
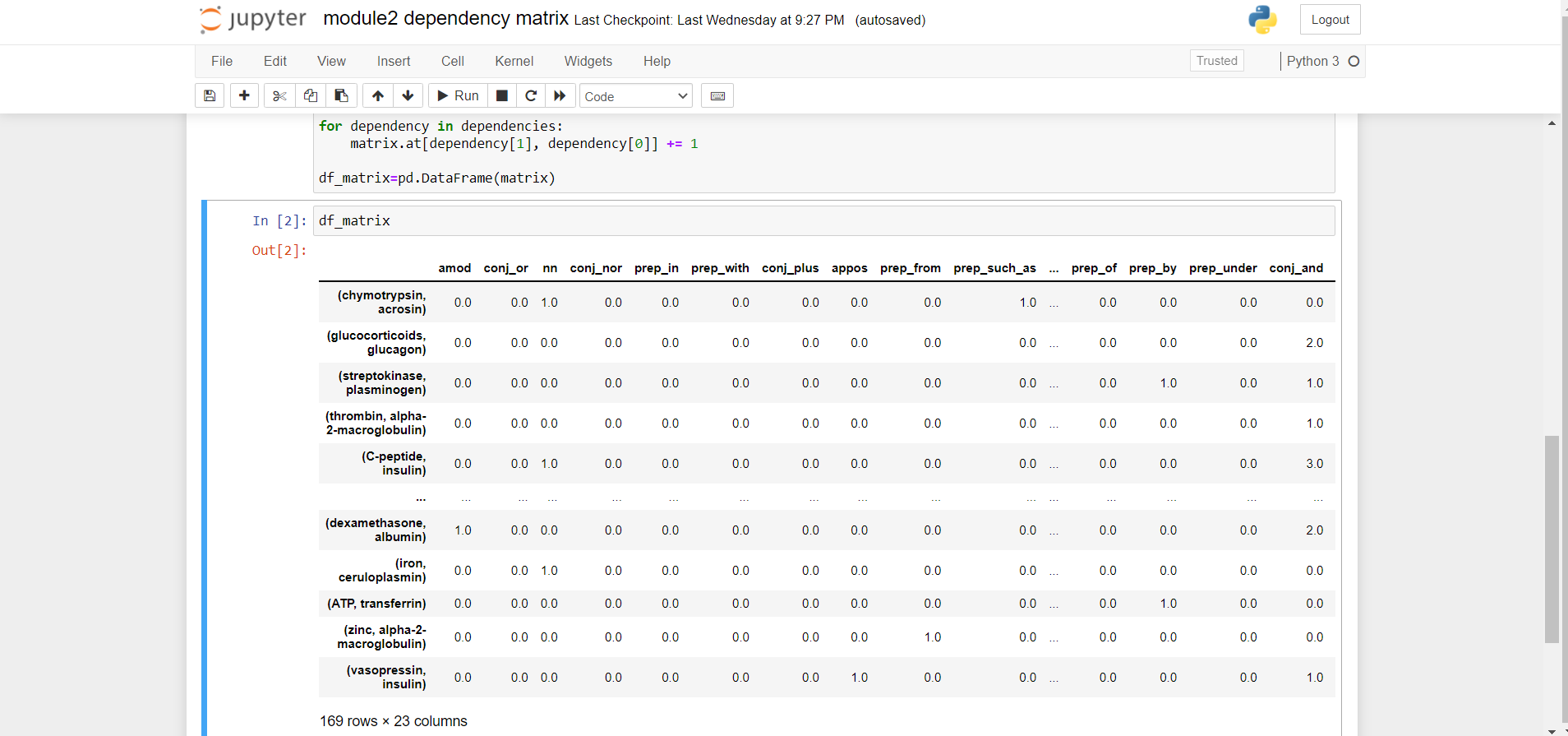
Created the matrix with drug-gene as rows & dependency relations as columns with the output of dependency parsing
-
Presented the overview of sparse matrix topic to the team wide journal club.
Detailed Statement of Tasks Completed:
- While working on dependency parsing task with java GUI based system in my windows system I faced some difficulties. So I used ubuntu subsystem. Then also I got an error “X11 forwarding not enabled” though it was enabled. I tried to enable it using SSH but again got some error. After I just tried to execute the stanford parser.jar file & I was able to do the dependency parsing task using Java GUI system. While following the instructions for dependency parsing what colin has given I got some errors in Windows machine but it worked for Linux system. I was able to store the output in “wordsAndTags, penn ,typedDependencies” formats. Then I used the typed dependency format output for creating the dependency matrix. After running dependency parsing task on more than 2000 Medline sentences I got 169 drug-gene pairs & 23 unique dependency relations in the dependency matrix.
Goals for the upcoming week:
Run EBC algorithm with the help of Dependency Matrix
Module3
Concise overview of things learned:
Technical area:
-
Re-read the EBC section of research paper & watched Colin’s video on EBC to get a better understanding of EBC algorithm
-
Understood how to run EBC Algorithm & Learned about EBC Scoring Rule.
-
Understood how to import different classes of python files to another python files.
Tools:
EBC module
Soft-skills:
- Improved communication skills while interacting with other team members during team meetings.
Achievement highlights:
-
Successfully ran the EBC Algorithm & got the cluster assignments of drug-gene pairs & dependency paths.
-
With the help of cluster assignments of drug-gene pairs created the N by N Co-occurrence Matrix of drug-gene pairs.
Detailed Statement of Tasks Completed:
My task was to complete Unsupervised step of EBC for my team. After running EBC algorithm on “matrix-ebc-paper-dense.tsv”(3514 drug-gene)[given in researcher’s EBC Github repo] I got 2 types of cluster assignment → 1) drug-gene pair cluster & 2) dependency path cluster.
For creating N by N Co-occurrency Matrix of drug-gene pairs we need drug-gene pair cluster assignments .Firstly I created a N By N matrix with all zeros. After 1 run of EBC I got 1 row of (N=3514) drug-gene cluster assignments. So my logic was firstly to access all the drug-gene cluster assignments (run for loop (i th) N times) & store it as list & then compare cluster number of every pair with other pairs[from that list of clusters]. For this I ran inner for loop (j th) which will run in range(i,N). For first iteration of inner for loop (j th) it will check if there is any drug-gene pair with same cluster number as first pair & will increment that cell of the matrix [i,j ] with 1. For next iteration it will check for 2nd pair cluster & so on upto n times. Diagonal of matrix will be equal to the number of EBC runs. Because in every run same pair will always co-cluster with that pair. Rows & Columns of the matrix will be the same drug-gene pair So the matrix will be symmetric. I ran the EBC algorithm 1000 times so diagonal is all 1000.
One of my team members Matthew implemented the EBC scoring. I learned from him & implemented the same. Seed Set Pairs are all from drugbank. Test sets have a 50-50 split of sets in drugbank and not in drugbank. All drugbank test set pairs will be mutually exclusive of seed set pairs. After getting the co-occurrence matrix we need to add seed set indicators (1 if present in drugbank , otherwise 0).
Then each test set and seed set pair will be scored. We can get co-occurrences of every test set member from co-occurrence matrix & sort them to get ranks.
According to research paper, For each test set Ti, rank all n rows of the data matrix based on how often they co-cluster with Ti. This produces a ranking Ri of length in in which pairs that frequently co-cluster with Ti are assigned high ranks and those that seldom cluster get low ranks.1 is the most frequent. N is the least frequent.
The score for Ti is the ranksum of the member sof the seed set, S, within this list.
Goals for the upcoming week:
Create Dendograms from co-occurrence Matrix
Module4
Concise overview of things learned:
Technical area:
- Learned the Intuition behind Agglomerative Clustering, how to use RStudio for creating dendograms from Colin’s video.
Tools:
RStudio, ape, purrr, protoclust package
Soft-skills:
- Improved communication skills while interacting with other team members during team meetings.
Achievement highlights:
- Installed RStudio & created the dendograms using agglomerative clustering.
Detailed Statement of Tasks Completed:
- Firstly calculated correlation & distance metric from N by N co-occurrence Matrix which I got from “matrix-ebc-paper-dense.tsv” dataset(3514 drug-gene) [given in researcher’s EBC Github repo]. Agglomerative Clustering is basically pairing cluster from bottom to higher frequency. Here the used cluster number is 25.


This is the plotted dendogram. From this dendogram we get to know whether drug-gene pairs are from Drugbank & PharmGKB , Cluster 2 mainly refer to inhibitor & subcluster antagonist, Cluster 6
mainly refer to inhibitor & subcluster agonist ,Cluster 7 mainly refer to activation relationship such as enhanced, simulated, reduced etc