Level 1 Module 3 Self Assessment
Technical Area:
- Extracted more data from the forum (all the data from the whole forum; our group split the work, and then one person combined everything into one csv–’combined_csv.csv’ )
- Picked the important features from the dataframe stored in the CSV file
- Removed the ‘commenters,’ ‘views,’ and ‘author’ features.
- Cleaned the data by removing the punctuation, unnecessary numbers, removing stopwords, and lowercasing the text.
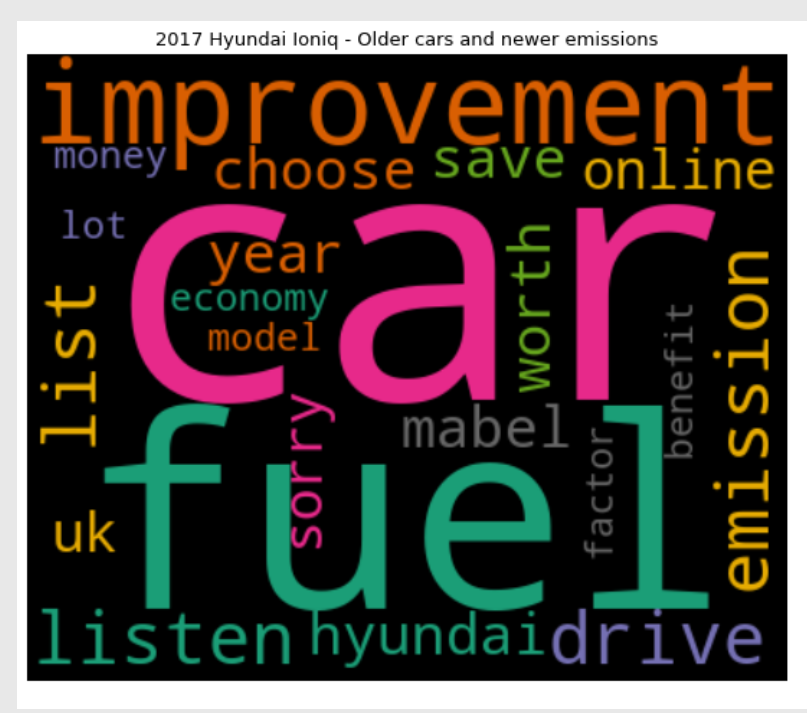
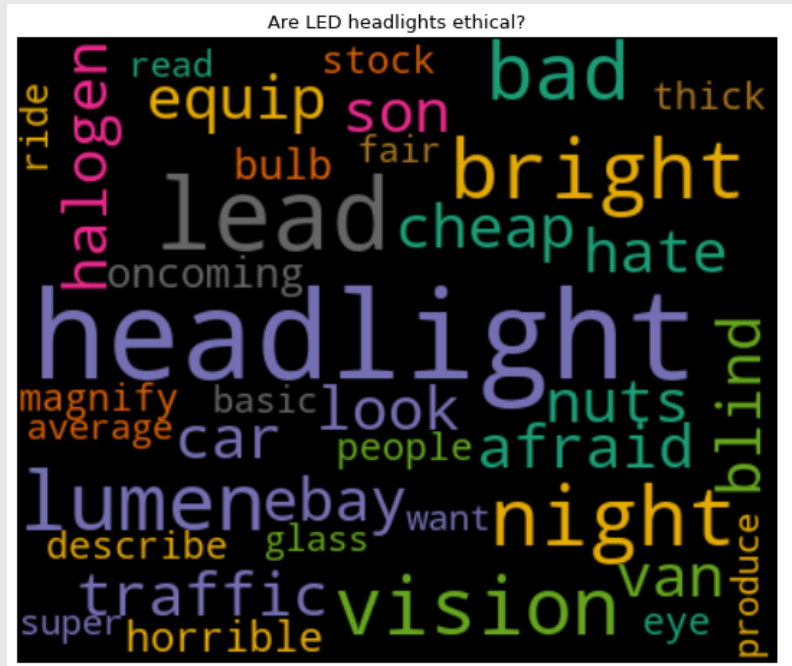
- Performed EDA on our data→ creating Word Clouds and Bigrams
- Extracted insights about our data through EDA.
- Split the data (80% training, 20% testing)
- Created classification models on our data with logistic regression, naive bayes, and decision tree.
- Calculated precision, recall, and f-1 score for each model.
- Logistic regression had the best outcome.
Tools:
- Visual Studio Code
- Python Packages (Numpy, NLTK, sklearn,…)
- Youtube (for tutorials)
Soft Skills:
- Remove certain columns from a dataframe. (cleaning the data)
- Removing stop words and punctuations from the text data.
- Getting insights from the data by performing EDA.
- training / testing the model which would predict the certain category a post belongs to.
- Fixing bugs in my code and asking my team members for help.
Achievements:
- Cleaning the data and removing unnecessary information.
- Changing dataset by removing some features.
- Successfully performing EDA on the model, and grabbing important insights about the data.
- Found out that the ‘tags’ feature plays an important role and increases the accuracy of the model.
- Creating the classification models and testing the accuracy of each model in predicting the category a post belongs to.
Tasks:
- Extracting more information from the forum (extracted all the information from the Car Talk Forum)
- Cleaned the data by removing stopwords, punctuations, and lowercase the text.
- Performed EDA on data by creating Word Clouds and Bigrams.
- Split the data into training and testing (80% training, 20% testing)
- Created classification models and calculated the accuracy, F1 score, recall, and precision.
EDA example: Created Word Clouds for all the topics on the Car Talk Forum. Some examples are shown below.
Level 1 Module 1 Self Assessment
Technical Area:
- I learned about the importance and uses of machine learning.
- Two approaches to Recommender Systems: Content Based Methods and Collaborative Filtering Methods. Common method is hybrid- which is a mix of both, and used in the industry.
- Data mining is the method where you extract data from a data set and transform it so that it can be used for Web Scraping.
- Scraping and Crawling are both methods for getting information from web pages
- API’s allow the user to explore data from the interface.
Tools:
- Beautiful Soup
- Discourse Forum: Car Talk
- Scrapy
- Visual Studio Code
- Python
Soft Skills
- Understood and explored the different libraries in Python and learned about NLP
- Looked through the Beautiful Soup documentation
- Understood the various recommender systems
Achievements:
- Revised over the Python Basics and Libraries
- Understood the new Python library–> Beautiful Soup
- Got introduced to Web Scraping, API’s, and Recommender Systems.
Tasks:
- Watched the videos for Machine Learning Basics
- Understood the new information on the different recommender systems.
- Learned about Web Scraping.
- Understood about Logistic Regression.
Level 1 Module 4 Self Assessment
Technical Area:
- Check if data was cleaned (no HTML tags or unnecessary words or numbers- mainly completed in Module 3)
- Tried training the BERT model (unsuccessful → became very complex)
- Made changes to the simple ML module, since I had errors.
Tools:
- Visual Studio Code
- Python Packages (Numpy, NLTK, sklearn,…)
- Youtube (for tutorials)
- Tutorials in Module 1 to familiarize in NLP
- Documentations on the advanced models
Soft Skills:
- Removing stop words and punctuations from the text data.
- Fixing bugs in my code and asking my team members for help.
- Learning about BERT modelling
- Searching the web if I didn’t understand a NLP concept
Achievements:
- Cleaning the data and removing unnecessary information.
- Getting familiar to BERT modeling
- Understanding what BERT is by watching Youtube videos and reading through documentations
- Along with BERT, tried understanding the other advanced models like ‘xlnet’, ‘xlm’, ‘roberta’, ‘distilbert’ and the difference between them.
- Tried training the BERT model.
Tasks:
- Looking through my code, fixing errors received from past modules.
- Understanding BERT, and what it is used for in Machine Learning.
- Understood the other advanced models like ‘xlnet’, ‘xlm’, ‘roberta’, ‘distilbert’
- Wasn’t able to understand how to successfully train the BERT model, so I need to still work on understanding that.
- I need to learn how to combine the advanced and simple models and discover how the results change.